SAP HANA 2.0 Training
Top 10 Reasons Customers Choose SAP HANA
SAP HANA is one of the fastest growing products in SAP’s history and is viewed by the industry as a breakthrough solution for in-memory databases. SAP HANA claims that it accelerates analytics and applications on a single, in-memory platform as well as combining databases, data processing, and application platform capabilities. SAP HANA is a next-generation business platform which brings together
- Business transactions
- Advanced analytics
- Social media
- Mobile experience
- Collaborative business
- Design connections
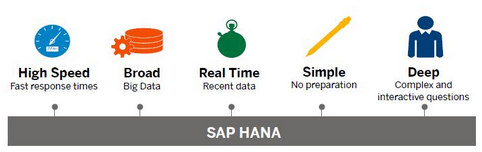
You may be thinking, “So what?” or “How does this help my business?” or “How can SAP HANA help my company make more money?”
In this article, we look at what we consider to be the top 10 reasons why customers should choose SAP HANA.
1. Speed:
“The speed SAP HANA enables is sudden and significant, and has the potential to transform entire business models.”
SAP HANA manages massive data volume at high speeds.
It delivers the “real” real-time enterprise through the most advanced in-memory technology.
SAP HANA provides a foundation on which to build a new generation of applications, enabling customers to analyze large quantities of data from virtually any source, in real time.
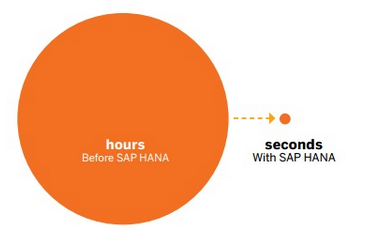
A live analysis by a consumer products company reveals how SAP HANA analyzes current point-of-sale data in real time—empowering this organization to review segmentation, merchandising, inventory management, and forecasting information at the speed of thought.

2. Real Time:
SAP HANA delivers the “real” real-time enterprise through the most advanced in-memory technology
Pull up-to-the-minute data from multiple sources. Evaluate options to balance financial, operational, and strategic goals based on today’s business
3. Any Data:
SAP HANA helps you to gain insights from structured and unstructured data.

SAP HANA integrates structured and unstructured data from internal and external sources, and can work on detailed data without aggregations.
4. Any Source:
SAP HANA provides multiple ways to load your data from existing data sources into SAP HANA.
SAP HANA can be integrated into a wide range of enterprise environments, allowing it to handle data from Oracle databases, Microsoft SQL Server, and IBM DB2.
5. Insight - Unlock new insights with predictive, complex analysis:
Before SAP HANA, analytics meant:
- Preconfigured dashboards based on fixed business requirements.
- Long wait times to produce custom reports.
- Reactive views and an inability to define future expectations.
With SAP HANA, you can:

Quickly and easily create ad-hoc views without needing to know the data or query type - allowing you to formulate your actions based on deep insights

Receive quick reactions to newly articulated queries so you can innovate new processes and business models to outpace the competition.
Enable state-of-the-art, interactive analyses such as simulations and pattern recognition to create measurable, targeted actions.
6. Innovation - The ultimate platform for business innovation:
SAP HANA is an early innovator for in-memory computing. Its configurability, easy integration, and revolutionary capabilities make it flexible enough for virtually anything your business requires.
Some examples of this include:
Energy Management
Utility companies use SAP HANA to process and analyze vast amounts of data generated by smart meter technology, improving customers’ energy efficiency, and driving sustainability initiatives.
Real-time Transit Routing
SAP HANA is helping research firms calculate optimal driving routes using real-time GPS data transmitted from thousands of taxis.
Software Piracy Detection and Prevention
Tech companies use SAP HANA to analyze large volumes of complex data to gain business insights into software piracy, develop preventive strategies, and recover revenue.
7. Simplicity - Fewer layers, simpler landscape, lower cost:
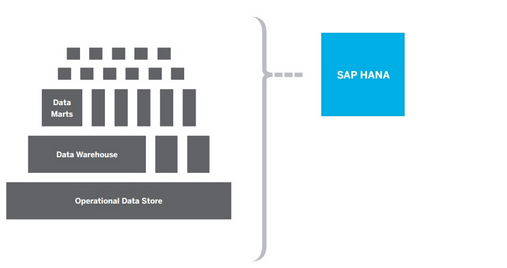
Reduce or eliminate the data aggregation, indexing, mapping and exchange-transfer-load (ETL) needed in complex data warehouses and marts.
Incorporate prepackaged business logic, in-memory calculations and optimization for multicore 64-bit processors.
Spend less on real-time computing
8. Cloud:

Step up to one of the world’s most advanced clouds.
SAP HANA powers SAP’s next- generation enterprise cloud.
Fast: A single-location stack removes latency – enabling real-time collaboration, processing, and planning.
Scalable: A highly robust cloud service allows quick deployment of current and next generation applications, scaled to your business needs.
Secure: We secure your data through the entire cloud solution with independently audited standards of data security and governance.
9. Cost: SAP HANA reduces your total IT cost so you can increase spending on innovation.
10. Choice:
SAP HANA provides you choice at every layer to work with your preferred partners.
- Run on the hardware of your choice.
- Work with the software you prefer.
Collaboration with a number of partners means that SAP can complete the software stacks of our diverse customer base in configurations that make sense for their business.
Plus, a variety of different options means that you won’t be locked in by a single provider.
Introduction to Database:
The main purpose of database is to store data and this data can be used for later purpose (analysis). Any big Enterprise we consider, they always store their business data into database. So that they use this data for analyzing their business.
Any database like (Oracle, Ms Access, SQL Server, Sybase ……) always store data in form of a structure called “TABLE”.
Table: Table is set of ROWS and COLUMNS
Each Row in a table is referred as Record
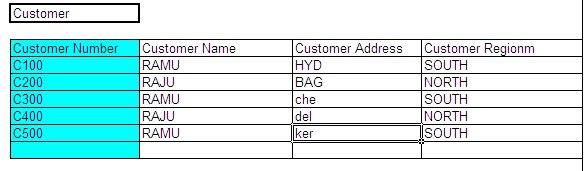
Primary Key:
It is a column in a database table which can maintain uniqueness for all the records in the table. It can be used to uniquely identify each and every record in the table
In above example: In the Customer Table the “Customer Number” is the Primary Key.
Every table must have a Primary Key (In Exceptional Cases we can have a table without a primary)
We have 2 types of columns in a table.
1) Key Column
2) Non - Key Column
Key Column:- Column which is a part of Primary Key.
Non - Key Column:- Column which is not a part of Primary Key.
All Non - Key Columns act as Attributes or Properties for Key Column.
Applications & Types:
Any application will have 4 aspects:
Any application will have 4 aspects:
- PL + database + OS + Concept
- Programming Language is used to design the frontend (i.e, Interface screens &Application logic)
- Database is used to design the backend to store data
- Operating system to run the application
- Concept is the reason for what the application is designed for
We have 2 types of applications:
- OLTP
- OLAP
OLTP [Online Transaction Process]:
OLTP applications are mainly to record all the transactions of the business
OLTP applications are mainly to record all the transactions of the business
OLAP [Online Analytical Processing]:
OLAP application takes in all the transaction data from different OLTP applications
and provides the reports for analysis.
There are some differences are there between OLTP and OLAP.
OLTP OLAP
1) Two dimensional model 1) Multi dimensional model
2) Day-to-Day Transactions 2) Historical data tractions also
3) Application oriented 3) Subject oriented
4) Users -> Thousands 4) Users - > Hundreds
5) DB size -> 100MB – 1GB 5) DB size -> 100GB-1TB
6) Redundancy 6) No Redundancy
7) No security 7) Security
Database design in OLAP:
In OLAP applications we store data in MDM [Multi Dimensional Format] by using the following models:
- Start Schema or Traditional Star schema
- Extended Start schema or BW Star schema or BI star schema
- Snow Flake
- Hybrid
Star Schema:

- Star schema is an MDM ( Multi Dimensional Model ) which contains Fact table / Transaction data Table at the center, surrounded by Dimension tables / Master Data Tables existing within the Cube.
- These Dimension Tables / Master Data Tables are linked to the Fact table / Transaction data table with Primary Key – Foreign Key Relationship.
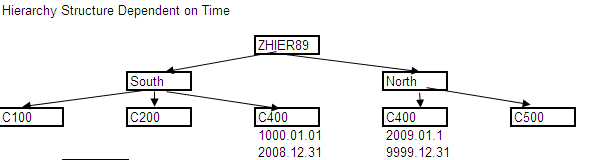
Hierarchies:
When do we go for hierarchies.
When the Characteristics are related as 1:M and in the Reporting if we need to display the values by using hierarchies (Tree like display)
Hierarchies:
Software Engineering process:
Whenever we develop a software we follow the SDLC cycle . SDLC contains 5 steps:
- Requirement Gathering
- Design
- Develop
- Testing
- Deploy
- Maintenance & Support
Requirement Gathering:
At this phase we gather the requirements from the end users and understand the business process.
Design:
As we know every application will have the Front End (Interface Screens) & Back end (Database). As part of this phase we will have to design the Front end screens and Design the Database (Database design is referred in the Next Section)
Develop
At this phase by using some Programming Language & some database we develop the software.
Testing
At this phase we test the software, weather the software is working as per the user requirements or not.
Deploy
Once the Software is tested perfectly we deploy the software at the client location. So that the business can start using the software.
Maintenance & Support:
Once the software is deployed, we will have to provide the Maintenance & Support for any issues what the client/ Business faces.
Testing
At this phase we test the software, weather the software is working as per the user requirements or not.
Deploy
Once the Software is tested perfectly we deploy the software at the client location. So that the business can start using the software.
Maintenance & Support:
Once the software is deployed, we will have to provide the Maintenance & Support for any issues what the client/ Business faces.
SAP HANA 1.0 SP09 DEVELOPMENT
HANA – High Performance Analytics Appliance
SAP HANA was implement in Nov 2011 and its adding with many Support Packs, Current Support Pack: SAP HANA 1.0 SP12 .
SAP HANA is an in-memory database:
- It is a combination of hardware and software made to process massive real time data using In-Memory computing.
- It combines row-based, column-based database technology.
- Data now resides in main-memory (RAM) and no longer on a hard disk.
- It’s best suited for performing real-time analytics, and developing and deploying real-time applications.
An in-memory database means all the data is stored in the memory (RAM). This is no time wasted in loading the data from hard-disk to RAM or while processing keeping some data in RAM and temporary some data on disk. Everything is in-memory all the time, which gives the CPUs quick access to data for processing.
The speed advantages offered by this RAM storage system are further accelerated by the use of multi-core CPUs, and multiple CPUs per board, and multiple boards per server appliance.
Complex calculations on data are not carried out in the application layer, but are moved to the database.
The speed advantages offered by this RAM storage system are further accelerated by the use of multi-core CPUs, and multiple CPUs per board, and multiple boards per server appliance.
Complex calculations on data are not carried out in the application layer, but are moved to the database.
OLTP - Online Transactional Process (Only Current Data, and cannot handle more complex logics)
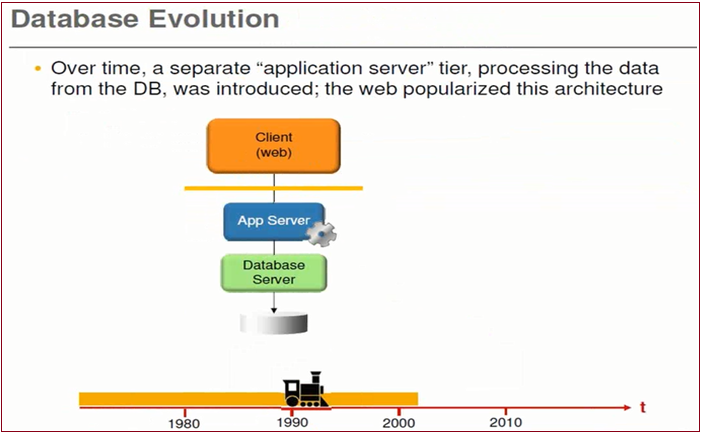
OLAP - Online Analytical Process (Can handle Current and Historical Data, Due to huge volume generating reports would take long time, (Data retrieves from Hard Disk), While by using HANA Platform data is retrieved from RAM.
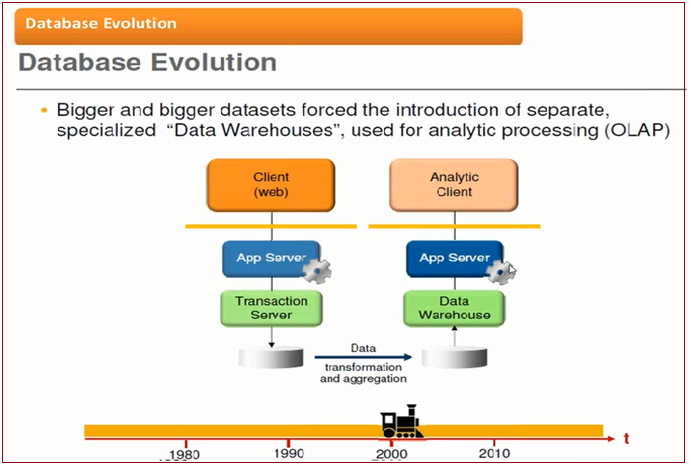
SAP tried with many theqnue’s, like Performance Tuning, BIA. So on.
For SAP BW/BI Oracle BI, DB2 data resided in table’s ( RDBMS, Oracle, DB2 ) as tables through Data flies (Data Storage block’s)
In HANA by using parallel processing and running reports by ram, performance will be very high.
Major Advantages in SAP HANA
1. Reading Data From RAM
2. SQL Console (Tables, Views1. Attribute View , 2. Analytical view . 3 Calc. View)
3. Column Storage in SAP HANA (1. Row Store , 2. Column Store , 3. Table Type )
1. In Memory Data Base (IMDB)
By using in memory data base data is retrieved directly from RAM. (a Copy of Data will be stored in Hard disk, for any unexpected server shutdown.) 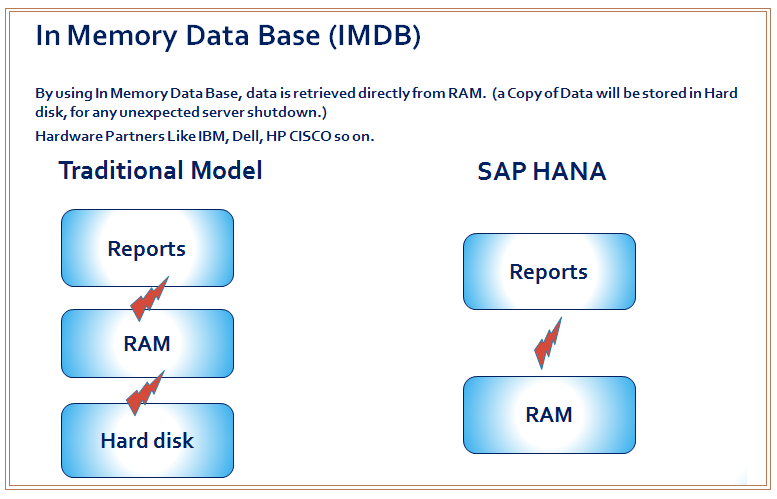
SAP HANA Hardware
SAP HANA is a combination of hardware and software made to process massive real time data using In-Memory computing. To leverage the full power of the SAP HANA platform, you need the right hardware infrastructure.
The SAP HANA can only be installed and configured by certified hardware partners.
SAP HANA Hardware Partners:
Currently SAP HANA Hardware partners are:

2. SQL Console
Introduction of SQL Script in HANA
- The SAP HANA database has its own scripting language named SQLScript.
- SQLScript is a collection of extensions to Structured Query Language (SQL).
It is used to push down data intensive logic into the database
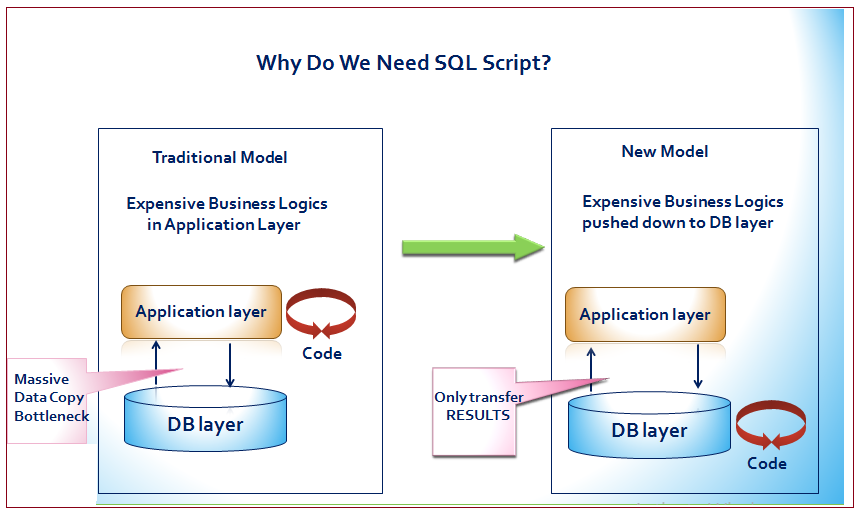
Why Do We Need SQLScript?
The main goal of SQLScript is to allow the execution of data intensive calculations inside SAP HANA.
There are two reasons why this is required to achieve the best performance:
- Moving calculations to the database layer eliminates the need to transfer large amounts of data from the database to the application
- Calculations need to be executed in the database layer to get the maximum benefit from SAP HANA features such as fast column operations, query optimization and parallel execution.
If applications fetch data as sets of rows for processing on application level they will not benefit from these features
3. Row Data Storage Vs Column Storage
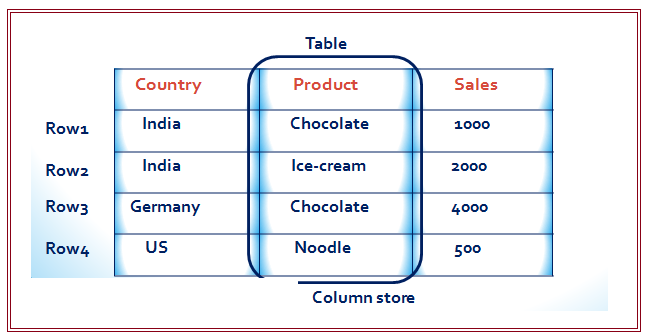
Relational databases typically use row-based data storage. However Column-based storage is more suitable for many business applications. SAP HANA supports both row-based and column-based storage, and is particularly optimized for column-based storage.
As shown in the figure below, a database table is conceptually a two-dimensional structure composed of cells arranged in rows and columns.
Because computer memory is structured linearly, there are two options for the sequences of cell values stored in contiguous memory locations:
Row Storage – It stores table records in a sequence of rows.
Column Storage – It stores table records in a sequence of columns i.e. the entries of a column is stored in contiguous memory locations.
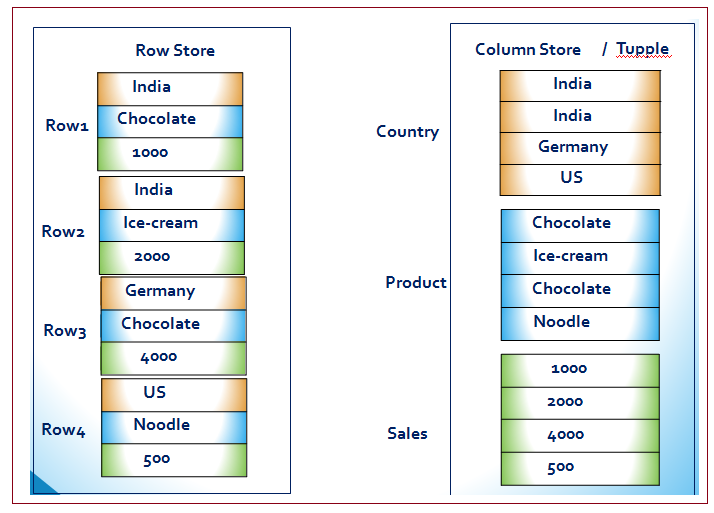
Traditional databases store data simply in rows. The HANA in-memory database stores data in both rows and columns. It is this combination of both storage approaches that produces the speed, flexibility and performance of the HANA database.
Advantages of column-based tables:
Faster Data Access:
Only affected columns have to be read during the selection process of a query. Any of the columns can serve as an index.
Better Compression:
Columnar data storage allows highly efficient compression because the majority of the columns contain only few distinct values (compared to number of rows).
Better parallel Processing:
In a column store, data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core
Advantages and disadvantages of row-based tables:
Row based tables have advantages in the following circumstances:
• The application needs to only process a single record at one time (many selects and/or updates of single records).
• The application typically needs to access a complete record (or row).
• Neither aggregations nor fast searching are required.
• The table has a small number of rows (e. g. configuration tables, system tables).
Row based tables have dis-advantages in the following circumstances:
- In case of analytic applications where aggregation are used and fast search and processing is required. In row based tables all data in a row has to be read even though the requirement may be to access data from a few columns.
ROW Store
- One of the relational engines to store data in row format.
- Pure in-memory store (Future versions will also have an option of disk based store)
- In memory object store (in future) for live cache functionality
- Transactions Version Memory is the heart of row store
Row store architecture
- Write operation mainly go into "Transactional Version Memory"
- INSERT also writes to persisted segment
- Moves visible version from memory to persisted segment
- Clears outdated record versions from Transactional Version memory
- Row Store tables have a primary index
- Row ID maps to primary key
- Secondary indexes can be created
- Row ID contains the segment and the page for the record
- Indexes in row store only exist in memory
- Index definition stored with table meta
Column Store
- Improves read functionality significantly, also improves write functionality
- Highly compressed data
- No real files, virtual files
- Optimizer and Executer – Handles queries and execution plan
- Delta data for fast write
- Asynchronous delta merge
- Consistent view Manager
- Main store compressed and read optimized – Data is read from Main Store
- Delta Store – Write optimized – for write operations.
- Asynchronous merge move the data from delta store to main store
- Compression by create dictionary and applying further compression methods
- Even during the merge operation, the columnar table will still be available for read and write operations. To fulfil this, a second delta and main storage are used internally
- Merge operation can also be triggered manually with an SQL command
Persistence Layer
- Peristence Layer is needed as Main memory is volatile
- Provides Backup and Restore functionality
- One Persistence Layer takes care of both row and column stores
- Regular Save Points
- Logs capturing DB transactions since last save point
- Actions during system restart
- Last savepoint must be restored plus undo logs must be read and uncommitted atransactions saved with last save point and apply redo logs
- Complete content of row store is loaded into memory during start procees
- Flags can be set for column store to specify which tables are loaded during system restart
HANA Solutions:
SAP HANA as Data warehouse solutions
HANA Modelling and information.
DataBase: Oracle, Teradata, Handoop, SAP HANA, ASE, IQ, MSS
ETL Tools: BODS (For BODS Non SAP Source will be preferred), SLT, DXC (Direct Extractor Connection) (STL & DXC SAP & CRM source will be preferred.
Reporting Tools: (Many users would prefer their own reporting tools; So SAP is providing a separate installation
MicroSoft Excel, Bex , Lumir, Bo (Webi, Cognos, Crystal So on )
SAP bW 7.3 (HANA as a individual platform, and inbuilt memory performance, it can perform lesser usage of hard disk (Data stored as Data-files(Data-blocks)) when compared to the other Datawearhouse.
For upgradation we need to first migrate SAP BW/BI to BW 7.3 and further we need to Upgrade HANA Database.
1. HANA can be used for OLTP database also(It acts as a individual platform), As HANA Data-Base.
2. SAP HANA DataBase can be used for Small Scale Business such as Business One with low harddisk and RAM Maintaince.
3. SAP HANA on Cloud Computing.
Cloud Computing is a process of maintains servers at manly locations, and maintained wilth many clients (Data) for cost efficiency for small companies (Amazon Web Services)
4.For Medium Scale: HANA Enterprise Club.
SAP HANA XS (XS- Extended Application Services )
5. It is a platform we can develop applications like Mobile Apps, Web Applications (With logic JAVA, HTM, so on)
Only 2 % of cases we use SQL statements for HANA Development, So all the design will be graphical.
SAP HANA Combinations
HANA + BO
HANA + BW/BI
HANA + BODS
HANA + ABAP
HANA + HTML, Java Script , RDL (Extended Application Services )
HANA + Administration Any DBA, ETL, SAP Basis so on
Difference between SAP BW and SAP HANA
SAP BW
Multi Dimensional Models are implemented by creating Infocubes and DSO’s. System will generate tables whenever we create Cubes or DSO’s. (Dim and Fact tables)
- Data Modeling ( Designing of Cubes and DSO’s )
- ETL - Extraction Transforming and Loading
- Reporting (Bex reporting Tool – Default reporting tool for SAP BW)
SAP HANA Database
- Data Modelling
- Data Provisioning or Data Replication(ETL) ( DODS, SLT , DXC )
- Impl. Of Data Models ( Creation of Views )
- Reporting ( BO reporting, Lumira…)
- Here Data Models (Multi Dimensional) are implemented by Creating Information Views.
- Views created based on tables, These tables are Created manually or replicate from sources)
SAP HANA Architecture:
-
Layer 1
SAP HANA Log-Based Replication
Transaction Log Based Data Replication Using Sybase Replication.
This replication method is only recommended for customers that have been invited to use this
technology during the RTC of the SAP HANA 1.0 product delivery. If you are not part of this RTC group, SAP recommends using Trigger-Based Data Replication Using SAP Landscape Transformation (SLT) Replicator because of the rich feature set this replication technology offers.
technology during the RTC of the SAP HANA 1.0 product delivery. If you are not part of this RTC group, SAP recommends using Trigger-Based Data Replication Using SAP Landscape Transformation (SLT) Replicator because of the rich feature set this replication technology offers.
SLT - Extraction data from SAP and Non SAP systems to HANA Database. (Its Real-time, 0 Downtime required.)
BODS 4.0 (Old 3.2 No ABAP work flows)
BODS can extract data from any SAP and Non SAP Systems to HANA DB.
Layer 2
Calculation and Planning Engine.
Whenever we run Query, it translates to SQL and pushes to HANA DB and fetches the data.
Row and Colum Store
Table data can be store in form of Row or Colum based store. When we run query it hit’s both Row and Column level store.
Modeling: Here we are going to create views
Data Provisioning Techniques
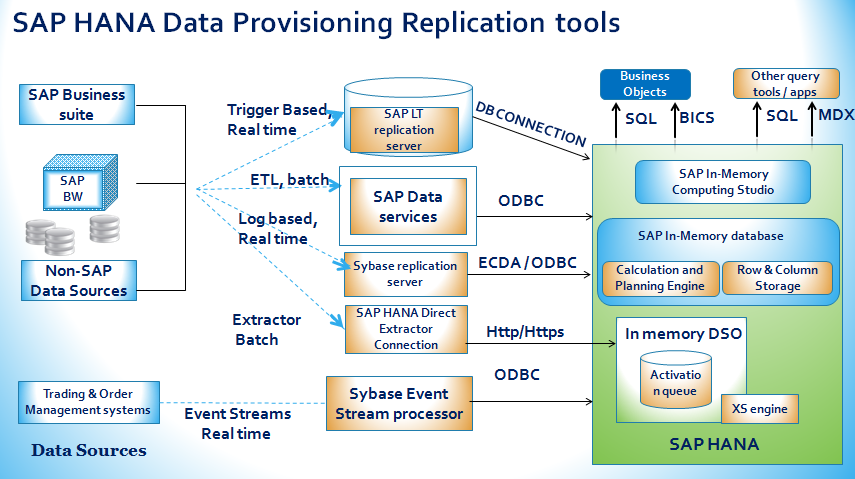
1. SAP SLT – (SAP LANDSCAPE TRANSFORMATION) REPLICATION
The SAP Landscape Transformation (LT) Replication Server is the SAP technology that allows us to load and replicate data in real-time from SAP source systems and non-SAP source systems to an SAP HANA environment.
The SAP LT Replication Server uses a trigger-based replication approach to pass data from the source system to the target system.
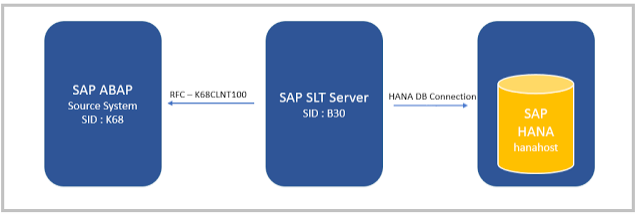
Advantage of SLT replication?
- SAP LT uses trigger based approach. Trigger-based approach has no measureable performance impact in source system.
- It provides transformation and filtering capability.
- It allows real-time (and scheduled) data replication, replicating only relevant data into HANA
- from SAP and non-SAP source systems.
- It is fully integrated with HANA Studio.
- Replication from multiple source systems to one HANA system is allowed, also from
- one source system to multiple HANA systems.
Continuous Delta Replication after Initial Load
2. BODS Business Objects Data Services
Basically whenever we are migrating production environment system to TDMS system. Here TDMS system can be used for SLT.
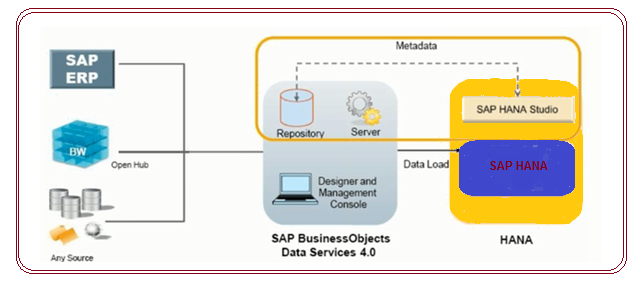
BODS 4.0 (Old 3.2): DS extraction is not real-time, but real-time. We need to schedule jobs accordingly
Advantages:
By Using DS we can extract data from any Source system (SAP & Non – SAP Systems )
BODS don’t store any data, Data stores in HANA DB.
Designer:
Repository:
- Local Repository: Mandatory reporting .When ever opening designer
- Central Repository: Moving objects between different landscape like transformations, work flow, data flow’s, job servers in repository.
3. DXC - Direct Extractor Connection
SAP HANA is one of the best and fastest appliances to get information on the fly but to do that it needs DATA. There are different techniques available to move the data into SAP HANA DB. In here we will discuss how we can load data to SAP HANA using Direct Extractor Connection (DXC).
SAP HANA Direct Extractor Connection (DXC) is providing foundational data models to SAP HANA, which is based on SAP Business Suite entities. Data in SAP Systems requires application logic to satisfy the Business Needs.SAP Business Content Data Source Extractors have been available for many years as a basis for data modeling and data acquisition for SAP Business Warehouse. Now, with DXC, these SAP Business Content Data Source Extractors are available to deliver data directly to SAP HANA.
A key point about DXC is it is batch-driven Process and in many use cases, batch-driven data acquisition at certain intervals is sufficient, for example, every 15 minutes.
DXC - No Additional license required, Cost Saving, No Server Maintained (DXC is Already in-built in source systems)
Huge cost saving is achieved in DXC.
Default Architecture : Using the Embedded BW System within ECC System

4 Smart Data Access
Companies are facing challenges to optimize cost and processes in order to sustain in this grim economic condition. Business has to be dynamic and agile to keep pace with the market and technology. Business has to get information in real time to make quick decision on time and at the same time, we need to keep control over cost for IT and Technology.
Keeping Business need in view, SAP has recently introduce Smart Data Access in SAP HANA which is a Virtualization Technique. This feature is introduced from SPS6 in SAP HANA. Smart Data Access enables SAP HANA to combine data from heterogeneous sources like Teradata, Sybase IQ, SAP Sybase Adaptive Service Enterprise and Hadoop.

Smart Data Access is a technology which enables remote data access as it they are local tables in HANA without copying data into SAP HANA. Data required from other sources will remain in virtual tables. Virtual tables will point to remote tables in different data sources. It will enable real time access to data regardless of its location and at same time, it will not effect SAP HANA database. Customers can then write SQL queries in SAP HANA, which could operate on virtual tables. The HANA query processor optimizes these queries, and executes the relevant part of the query in the target database, returns the results of the query to HANA, and completes the operation.
===========================================================
Backup and Recovery
SAP HANA is an in-memory database. This means all the data is in RAM. As we all know that RAM is a volatile memory and all the data get lost when power goes down.
This leads to a very obvious question:
This leads to a very obvious question:
What happens when power goes down in SAP HANA? Do we loose all the valuable data?
The answer is NO.
The answer is NO.
SAP HANA is an in-memory database which means all the data resides in RAM. But there is also a disc memory just for backup purpose.
In-memory computing is safe: The SAP HANA database holds the bulk of its data in memory for maximum performance, but still uses persistent storage (disk memory) to provide a fallback in case of failure.
In-memory computing is safe: The SAP HANA database holds the bulk of its data in memory for maximum performance, but still uses persistent storage (disk memory) to provide a fallback in case of failure.
Why Backup is Required?
In database technology, atomicity, consistency, isolation, and durability (ACID) is a set of requirements that guarantees that database transactions are processed reliably:
A transaction has to be atomic. That is, if part of a transaction fails, the entire transaction has to fail and leave the database state unchanged.
The consistency of a database must be preserved by the transactions that it performs.
Isolation ensures that no transaction is able to interfere with another transaction.
Durability means that after a transaction has been committed it will remain committed.
While the first three requirements are not affected by the in-memory concept, durability is a requirement that cannot be met by storing data in main memory alone.
Main memory is volatile storage. That is, it looses its content when it is out of electrical power. To make data persistent, it has to reside on non-volatile storage, such as hard drives, SSD, or Flash devices.
How Backup and Recovery Works in SAP HANA?
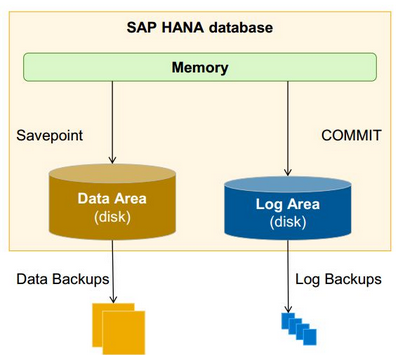
The main memory (RAM) in SAP HANA is divided into pages. When a transaction changes data, the corresponding pages are marked and written to disk storage in regular intervals.
In addition, a database log captures all changes made by transactions. Each committed transaction generates a log entry that is written to disk storage. This ensures that all transactions are permanent.
Figure below illustrates this. SAP HANA stores changed pages in savepoints, which are asynchronously written to disk storage in regular intervals (by default every 5 minutes).
The log is written synchronously. That is, a transaction does not return before the corresponding log entry has been written to persistent storage, in order to meet the durability requirement, as described above.
After a power failure, the database can be restarted like a disk-based database.
The database pages are restored from the savepoints, and then the database logs are applied (rolled forward) to restore the changes that were not captured in the savepoints.
This ensures that the database can be restored in memory to exactly the same state as before the power failure.
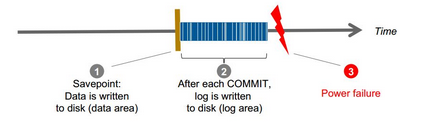
Data backup can be taken manually or can be scheduled.
Few Important Concepts:
What is Database Backup and Recovery
Backup and Recovery is the process of copying/storing data for the specific purpose of restoring. Backing up files can protect against accidental loss of user data, database corruption, hardware failures, and even natural disasters.
Savepoint:
A savepoint is the point at which data is written to disk as backup. This is a point from which the Database Engine can start applying changes contained in the backup disk during recovery after an unexpected shutdown or crash.
The database administrator determines the frequency of savepoints..
Data and Log:
Data backups
- Contain the current payload of the data volumes (data and undo information)
- Manual (SAP HANA studio, SQL commands), or scheduled (DBA Cockpit)
Log backups
- Contain the content of closed log segments; the backup catalog is also written as a log backup
- Automatic (asynchronous) whenever a log segment is full or the timeout for log backup has elapsed
What is SAP HANA Studio?
- The SAP HANA studio is an Eclipse-based development and administration tool for working with HANA.
- It enables technical users to manage the SAP HANA database, to create and manage
- user authorizations, to create new or modify existing models of data etc.
- It is a client tool, which can be used to access local or remote HANA system.
How to add new HANA system in HANA studio?
In order to connect to a SAP HANA system we need to know the Server Host ID and the Instance Number.
Also we need a Username & Password combination to connect to the instance.
The left side Navigator space shows all the HANA system added to the SAP HANA Studio.
Also we need a Username & Password combination to connect to the instance.
The left side Navigator space shows all the HANA system added to the SAP HANA Studio.
Steps to add new HANA system:
Right click in the Navigator space and click on Add System
Right click in the Navigator space and click on Add System
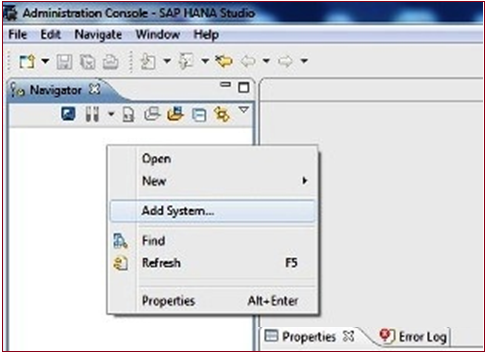
- Enter HANA system details, i.e. the Hostname & Instance Number and click Next.
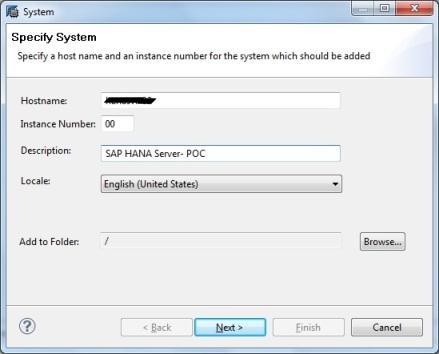
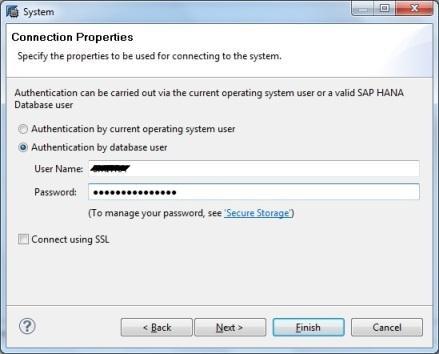
- Enter the database username & password to connect to the SAP HANA database. Click on Next and then Finish.
- The SAP HANA system now appears in the Navigator.
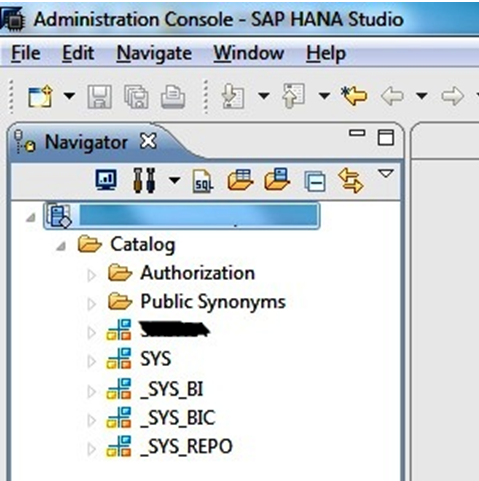
Qs. What is the difference between catalog and content?
In HANA Studio every HANA system has two main sub-nodes, Catalog and Content.
Catalog:
· The Catalog represents SAP HANA’s data dictionary, i. e. all data structures, tables, and data which can be used.
- All the physical tables and views can be found under the Catalog node.
Content:
- The Content represents the design-time repository which holds all information of data models created with the Modeler.
- Physically these models are stored in database tables which are also visible under Catalog. The Models are organized in Packages. The Contents node just provides a different view on the same physical data.
- The created Column Views are always located in schema _SYS_BIC, their metadata in schema _SYS_BI.
There is no 32 bit version of the repository client.
If you want to make use of the repository integration features, for example, in the Project Explorer view in the SAP HANA Development perspective, you must install the 64 bit version of the repository client.
If you want to make use of the repository integration features, for example, in the Project Explorer view in the SAP HANA Development perspective, you must install the 64 bit version of the repository client.
Qs. How can we set path to the repository client in HANA Studio?
HANA studio, choose Window –> Preferences –> SAP HANA Development –> Repository Access
Choose Browse and enter the path to the SAP HANA client executable, regi.exe. For example, C:Program Filessaphdbclientregi.exe
Choose Apply to enable the new setting.
Choose OK to save the settings.

Qs. How to start HANA Studio in Linux?
To start the SAP HANA studio, perform the following steps:
Open a shell and go to the installation directory, such as /usr/sap/hdbstudio
Execute the following command “./hdbstudio”. The SAP HANA studio starts.
To set the path to the repository client
In SAP HANA studio, choose Window Preferences SAP HANA Development Repository Access
Choose Browse… to enter the path to the SAP HANA client executable, regi. For example, /usr/sap/hdbclient
Choose Apply to enable the new setting.
Choose OK to save the settings.
Open a shell and go to the installation directory, such as /usr/sap/hdbstudio
Execute the following command “./hdbstudio”. The SAP HANA studio starts.
To set the path to the repository client
In SAP HANA studio, choose Window Preferences SAP HANA Development Repository Access
Choose Browse… to enter the path to the SAP HANA client executable, regi. For example, /usr/sap/hdbclient
Choose Apply to enable the new setting.
Choose OK to save the settings.
SAP HANA – Overview of Modeler Perspective
In SAP HANA studio, the SAP HANA Modeler perspective helps you create various types of information views, which defines your analytic model.
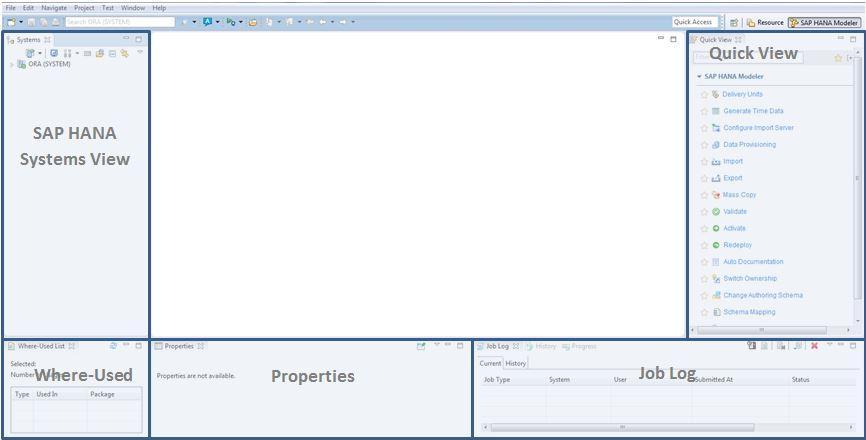
The SAP HANA Modeler perspective layout contains the following:
SAP HANA Systems view: A view of database or modeler objects, which you create from the Modelerperspective.
Quick View : A collection of shortcuts to execute common modeling tasks. If you close the Quick Viewpane, you can reopen it by selecting 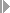 Help
Help  Quick View
Quick View
Properties pane: A view that displays all object properties.
Job Log view: A view that displays information related to requests entered for a job such as, validation, activation, and so on.
Where-Used view: A view that lists all objects where a selected object is used.
- SAP HANA studio is an eclipse based environment designed to provide platform for Development, Data Provisioning, Modeling and Administration on SAP HANA.
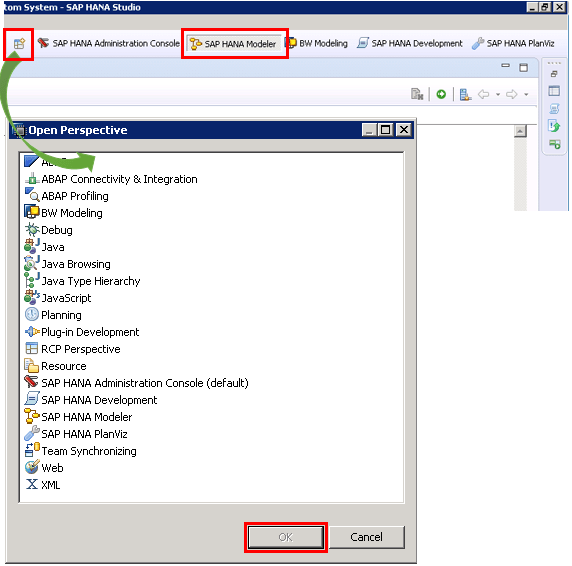
- One of the main feature we have in SAP HANA studio is perspective. SAP HANA Studio provides different types of perspectives which are specifically designed to perform certain tasks on SAP HANA Database.
- We can see the list of perspectives available in SAP HANA Studio by going to ‘Main Menu’ → ‘Window’ → ‘Open Perspective’ → ‘Other’ as shown.
- This gives us the below screen with list of perspectives available in SAP HANA Studio as shown in below image.
Some of the important perspectives that are frequently used are
1. ABAP:
- This perspective is used to build, debug and execute the ABAP programs like how we do in any SAP ECC system.
- Using this perspective one can switch between SAP GUI screen and eclipse screen any time and the SAP screen here provides all the functionalities that we get when we login into SAP system directly.
- This perspective doesn’t come as a default perspective along with SAP HANA studio.
2. BW Modeling:
- This perspective is used to build the BW modeling objects and maintain the BW system from HANA studio rather than logging into BW system separately
- This actually provides single point solution for BW modeling and administration.
- Some of the modeling objects that we can create using BW modeling tools in HANA Studio are Advanced DSO, Composite Provider and Open ODS View.
3. Debug:
- This perspectives helps us in debugging the codes we write while building web applications using developments perspective
- Example: To view source code, monitor or modify variables, and set break points
4. SAP HANA Development:
- This perspective is used to perform all the tasks related to application development on SAP HANA XS
- For example: to manage application-development projects, display content of application packages, and browse SAP HANA repository.
- You can also define your data-persistence model here by using design-time artifacts to define tables, views, sequences, and schemas.
- Note: This is the most frequently used perspective by developers in SAP HANA.
5. SAP HANA Modeler:
- This perspective is used to build analytic models like attribute view, analytic view, and calculation view and so on.
- Using this we can also maintain the database objects like tables, views, sequences, indexes and so on and administering the real-time replication using SLT.
Note: This is the most frequently used perspective by modelers in SAP HANA.
6. SAP HANA Administration Console:
- This perspective provides different elements to administer the SAP HANA database from the threads that are running on server to the system level configuration.
- Note: This is the most frequently used perspective by administrators in SAP HANA.
7. SAP HANA PlanViz:
- This perspective is used to do performance analysis on the modeling objects we create by executing visualize plan.
- This perspective will be called by default when we execute ‘Visualize Plan’ from SQL console on any HANA model or SQL statement.
- Note: This perspective is frequently used by modelers in SAP HANA.
8. Team Synchronizing:
- This perspective is used to synchronize the development artifacts we have created in local file system to SAP HANA repository.
- Note: This perspective is frequently used developers in SAP HANA.
In this article, we will look at Modeler perspective in SAP HANA studio and see different types of activities that can be performed from here.
- A Perspective consists of a set of views to make the work easy and each view provides different set of information.
- Modeler perspective in SAP HANA Studio consist of seven different views, they are
- Systems View
- Where-used List view
- Properties View
- History View
- Job Log View
- Progress View
- Quick View ( earlier Quick Launch)
- This below image shows the pictorial representation of Modeler perspective along with the views.
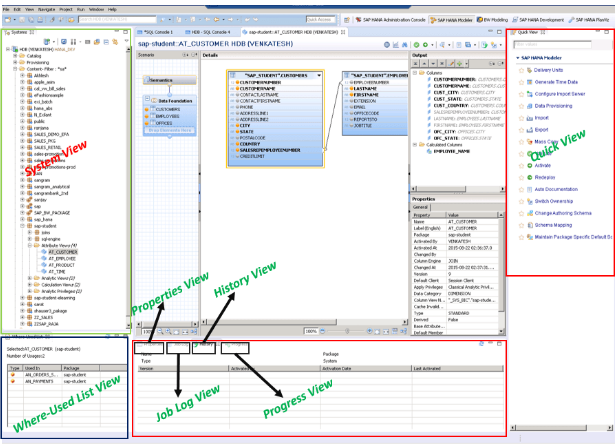
1. System View: Here we add our SAP HANA system connection information. Once we add the system, we can view the objects in that system categorized into four types.
- Catalog – Holds Database objects grouped under schemas.
- Provisioning – Administration and monitoring screen for Smart Data Access.
- Content – Holds Modeling objects grouped under packages.
- Security – Contains Users and Roles in the system.
2. Where-Used List View: This view provides the dependent object names for the object currently beings opened in the system. In the above image, where used list shows the list of dependent objects on AT_CUSTOMER attribute view.
- Note: This provides dependent objects information for the modeling objects. If you would like to know how to get where used list for all other types of objects, then go through article
3. Properties View: This provides the properties of the object we select in the system. This also shows properties for either modeling objects or SQL console in modeler perspective.
4. Job Log View: This view shows the number of jobs we have executed (including modeling objects validation and activation) during current login and details about those jobs like job details and status.
- Note: If we logoff and login then we won’t see anything under this view, however we can find them under history view.
5. History View: This view shows us the different types of jobs we have executed and its detailed view over a period of time.
6. Progress View: This view has the list of jobs that we are currently running on SAP HANA system. This view only shows active objects and jobs can also be cancelled from this view.
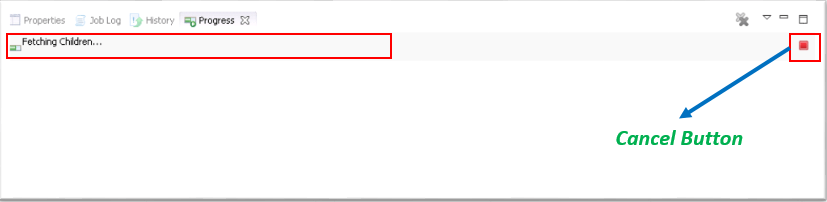
7. Quick View: This is very important view for modeler, because of the reason that we can perform a lot of activities that are very important for modeling from here. To know more about how to perform each activity that we have under Quick View screen, please go through the below articles.
How to open a View?
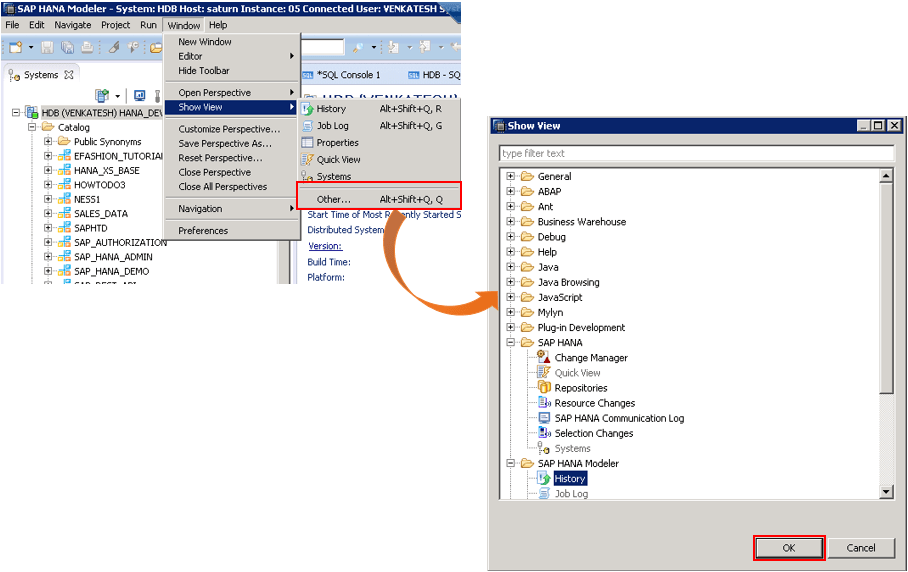
- If we feel like some of the views are missing in any perspective or need additional views we can get then by going into ‘Main Menu’ → ‘Window’ → ‘Show View’ → ‘Other’.
- This will give us the screen with list of different views categorized into folders available in HANA Studio. We can choose the view we would like have in the Studio and click ‘ok’ to see that in Studio.
How to minimize a view?
Sometimes when we are building complex models in SAP HANA or writing big SQL statements we might feel uncomfortable with all these views residing all around.
Sometimes when we are building complex models in SAP HANA or writing big SQL statements we might feel uncomfortable with all these views residing all around.
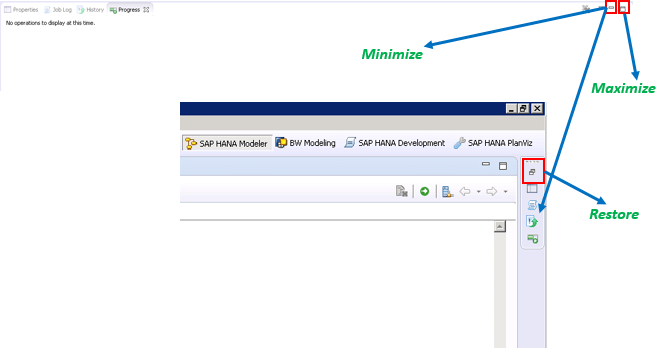
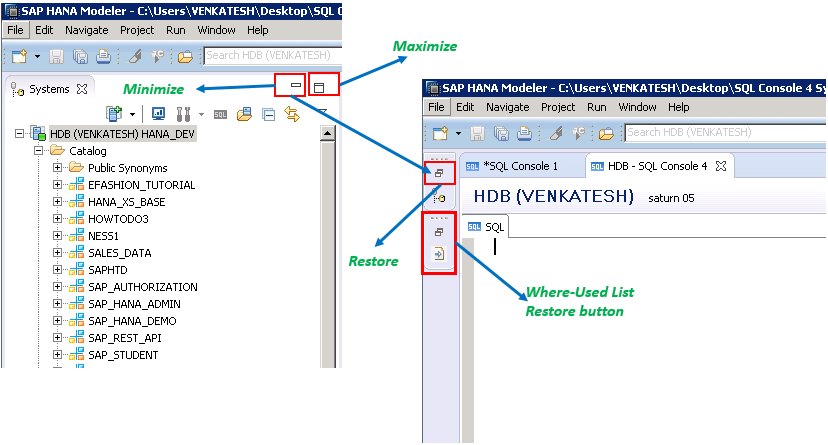
- We can minimize a view and also restore it whenever we need using the ‘minimize’ and ‘restore’ buttons available.
- Note: Minimizing the ‘systems view’ and ‘Where-Used List view’ places extra icons on left side top of the HANA studio and for other views it is going to be on right side top.
- We don’t have minimize option for ‘Quick View’. This can be closed and reopened from ‘Main Menu’ → ‘Help’ → ‘Quick View’.
Properties/Job Log/History/Progress View:
Systems View & Where-Used List:
How to switch between perspectives:
- We can quickly switch between multiple perspectives using the option we have on top of the SAP HANA Studio as shown below.
- Note: The perspective we are currently using will be highlighted on top as shown above in the above image.
With this we have seen details about how the modeler perspective looks in SAP HANA studio and the different types of views it has.
Thank you for reading and hope this information is helpful. Please do share with your friends if you feel the information is useful.
Happy Learning.
SAP HANA Views
Package: Packages are just like Folders; these are Group of related information objects/Modeling objects.
Packages are of Two Types
- Structural Package
Here we can create only sub-packages (No Views Can be created)
- Non-Structural Package
We can create any object. (Views can be created)
Example 1:
Under SALES.(Structural Package)
Sales (Non-Structural Package)
- Attribute views
- Analytic views
- Calculation views
Delivery (Non-Structural Package)
- Attribute views
- Analytic views
- Calculation views
Billing (Non-Structural Package)
- Attribute views
- Analytic views
- Calculation views
Example 2:
Under Fin. Acc.(Structural Package)
Accounts Payable (Non-Structural Package)
- Attribute views
- Analytic views
- Calculation views
Accounts Receivable (Non-Structural Package)
- Attribute views
- Analytic views
- Calculation views
G/L Account (Non-Structural Package)
- Attribute views
- Analytic views
- Calculation views
Fixed Assets (Non-Structural Package)
- Attribute views
- Analytic views
- Calculation views
Creating Information Views (Modeling objects)
SAP HANA Information Modeling which also known as SAP HANA Data Modeling is the heart of HANA application development. You can create modeling views on top of database tables and implement business logic to create a meaningful report.
SAP HANA Information Modeling which also known as SAP HANA Data Modeling is the heart of HANA application development. You can create modeling views on top of database tables and implement business logic to create a meaningful report.
- These modeling views can be consumed via Java or HTML based applications or SAP HANA native applications. You can also use SAP tools like SAP Lumira or Analysis Office to directly connect to HANA and report modeling views. It is also possible to use 3rd party tools like MS-Excel to connect to HANA and create your report.
Attribute views
- Attribute views are created below the packages. Attribute Views are used to present master data (if required along with text and Hierarchy data).
- Attribute Views can be also viewed for reporting a dimension in multidimensional modeling.
- In most cases used to model master data like entities (like KNA1- Customer Master Data , MARA - Material Master Data ....Product, Employee, Business Partner)
- Highly re-used and shared in Analytical View and Calculation Views
- Attribute views are also called as Joint views.
- Master Data (along with Text data and Hierarchy Data)
- Dimension
- Tables can be from multiple schemas
Analytic View:
- Analytic views are star schemas or fact tables surrounded by dimensions, calculations or restricted measures.
- In the language on SAP BW analytical views can be roughly compared with Info Cubes.
- Analytic views are typically defined on at least one fact table/Transaction Data that contains transactional data along with number of tables or attribute views.
- Analytical Views can be also viewed for reporting a dimension in multidimensional modeling.
- Analytical Views are called as OLAP Views.
Limitation
- In one Analytical View we can select measures from only on fact table or transaction data.
Calculation Views:
- Calculation Views can be used for more complex analysis requirements, which cannot be managed by attribute view or analytical view.
- Calculation views are composite views used on top of analytical and attribute views
- Ex- Combination of data from multiple fact tables/Transaction Data Tables, multiple analytical views or any other combination’s
To Create a Calculation View we can select tables (Master Data or Transaction Data). & Views (Attribute, Analytical & Calc View’s).
Calculation View can be created in 2 Ways.
- Graphical Calculation Views
- Scripted Calculation Views
Types of Schemas
There are 3 types of schemas.
- User Defined Schema
- System Defined Schema
- SLT Derived Schema
1. User Defined Schema:
These are created by user (DBA or System Administrator)
2.System Defined Schema:
These schemas are delivered with the SAP HANA database and contains HANA system information. There are system schemas like _SYS_BIC, _SYS_BI, _SYS_REPO, _SYS_STATISTICS etc.
System Generated Schemas

_SYS_BIC: This schema contains all the columns views of activated objects. When the user activates the Attribute View/Analytic View/Calculation View/Analytic Privilege /Procedure,Decision Tables... the respective run-time objects are created under _SYS_BIC/ Column Views.
_SYS_REPO: Whatever the objects are there in the system is available in repository. This schema contains the list of Activated objects, Inactive Objects, Package details and Runtime Objects information etc.
Also _SYS_REPO user must have SELECT privilege with grant option on the data schama.
_SYS_BI: This schema stores all the metadata of created column Views. It contains the tables for created Variables, Time Data (Fiscal, Gregorian), Schema Mapping and Content Mapping tables.
_SYS_STATISTICS:
This schema contains all the system configurations and parameters.
_SYS_XS:
This schema is used for SAP HANA Extended Application Services.
3. SLT Derived Schema:
When SLT is configured, it creates schema in HANA system. All the tables replicated into HANA system are contained in this schema
==============================================================
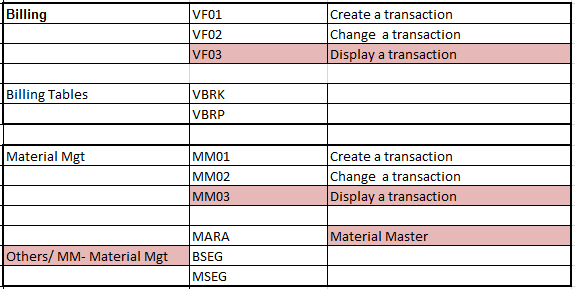
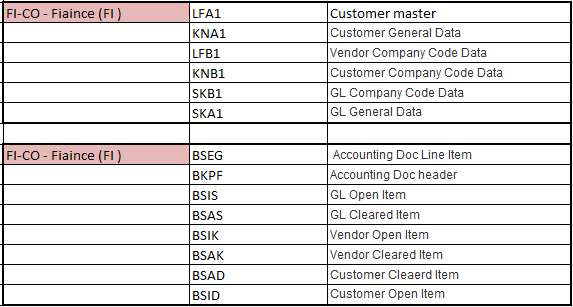
Important Tables in SAP System (ECC)